Multinomial Choice Models and the Indepdence of Irrelevant Alternatives#
import arviz as az
import matplotlib.pyplot as plt
import pandas as pd
from pymc_marketing.customer_choice.mnl_logit import MNLogit
from pymc_marketing.paths import data_dir
az.style.use("arviz-darkgrid")
plt.rcParams["figure.figsize"] = [12, 7]
plt.rcParams["figure.dpi"] = 100
Discrete choice models are a class of statistical models used to analyze and predict choices made by individuals among a finite set of alternatives. The set of alternatives ussually represent a choice between “products” broadly construed.
These models are grounded in utility maximization theory, where each option provides a certain level of utility to the decision-maker, and the option with the highest perceived utility is chosen.
Discrete choice models are widely applied in fields like transportation, marketing, and health economics to understand behavior and inform policy or design. Common variants include the multinomial logit, nested logit, and mixed logit models, each capturing different aspects of choice behavior, such as similarity among alternatives or individual heterogeneity. In this notebook we will demonstrate how to specify the multinomial logit model and highlight a property of this model known as the Independence of Irrelevant Alternatives.
The Data#
We will examine a case of choices between heating systems. This data is drawn from an example in the R package mlogit.
Note the data has been formatted in a “wide” fashion where each row represents a choice scenario characterised by (a) the chosen outcome depvar, (b) the product attributes: installation costs (ic_x) and operating costs (oc_x) and (c) fixed attributs of the agent making the choice e.g. the consumer’s income and rooms.
data_path = data_dir / "choice_wide_heating.csv"
df = pd.read_csv(data_path)
df
| idcase | depvar | ic_gc | ic_gr | ic_ec | ic_er | ic_hp | oc_gc | oc_gr | oc_ec | oc_er | oc_hp | income | agehed | rooms | region | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | gc | 866.00 | 962.64 | 859.90 | 995.76 | 1135.50 | 199.69 | 151.72 | 553.34 | 505.60 | 237.88 | 7 | 25 | 6 | ncostl |
| 1 | 2 | gc | 727.93 | 758.89 | 796.82 | 894.69 | 968.90 | 168.66 | 168.66 | 520.24 | 486.49 | 199.19 | 5 | 60 | 5 | scostl |
| 2 | 3 | gc | 599.48 | 783.05 | 719.86 | 900.11 | 1048.30 | 165.58 | 137.80 | 439.06 | 404.74 | 171.47 | 4 | 65 | 2 | ncostl |
| 3 | 4 | er | 835.17 | 793.06 | 761.25 | 831.04 | 1048.70 | 180.88 | 147.14 | 483.00 | 425.22 | 222.95 | 2 | 50 | 4 | scostl |
| 4 | 5 | er | 755.59 | 846.29 | 858.86 | 985.64 | 883.05 | 174.91 | 138.90 | 404.41 | 389.52 | 178.49 | 2 | 25 | 6 | valley |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 895 | 896 | gc | 766.39 | 877.71 | 751.59 | 869.78 | 942.70 | 142.61 | 136.21 | 474.48 | 420.65 | 203.00 | 6 | 20 | 4 | mountn |
| 896 | 897 | gc | 1128.50 | 1167.80 | 1047.60 | 1292.60 | 1297.10 | 207.40 | 213.77 | 705.36 | 551.61 | 243.76 | 7 | 45 | 7 | scostl |
| 897 | 898 | gc | 787.10 | 1055.20 | 842.79 | 1041.30 | 1064.80 | 175.05 | 141.63 | 478.86 | 448.61 | 254.51 | 5 | 60 | 7 | scostl |
| 898 | 899 | gc | 860.56 | 1081.30 | 799.76 | 1123.20 | 1218.20 | 211.04 | 151.31 | 495.20 | 401.56 | 246.48 | 5 | 50 | 6 | scostl |
| 899 | 900 | gc | 893.94 | 1119.90 | 967.88 | 1091.70 | 1387.50 | 175.80 | 180.11 | 518.68 | 458.53 | 245.13 | 2 | 65 | 4 | ncostl |
900 rows × 16 columns
Seeing that we have 5 alternatives to choose from:
df["depvar"].value_counts()
depvar
gc 573
gr 129
er 84
ec 64
hp 50
Name: count, dtype: int64
The idea of discrete choice models is to determine how propensity to choose these products is driven by their observable attributes.
Utility Theory and Maximisation#
The general idea of these models is that an individuals’ choices among observed alternatives reflect the maximization of an underlying utility function. In this framework, each alternative in a choice set is associated with a latent utility composed of observable components (e.g., cost, travel time) and unobservable factors captured as random errors. Daniel McFadden formalized this approach using random utility models, including the multinomial logit model, which assumes that the unobserved components of utility follow an extreme value distribution. His models provided a rigorous econometric foundation for analyzing choice behavior from observed decisions, enabling estimation of how changes in attributes influence choice probabilities. This work earned McFadden the Nobel Prize in Economics in 2000 and has had lasting influence in transportation, marketing, and labor economics.
To specify our multinomial logit model we therefore specify the form of the utility equations that might drive consumers to purchase particular goods amongst a choice set. Note how we distinguish each of the individual alternatives and the alternative-specific-covariates and the individual-specific-covariates by using the | notation. This is a variant of the standard Wilkinson stlye formula notation for specifying regression models. Under the hood we fit N regression models for each of the N goods. These regressions are used to generate a Utility score which is fed through a softmax transform to give us probabilities of each particular choice. The most probable choice should be the one with the greatest predicted utility.
For more details on the background theory and varieties of utility specification see the PyMC example here
utility_formulas = [
"gc ~ ic_gc + oc_gc | income + rooms + agehed",
"gr ~ ic_gr + oc_gr | income + rooms + agehed",
"ec ~ ic_ec + oc_ec | income + rooms + agehed",
"er ~ ic_er + oc_er | income + rooms + agehed",
"hp ~ ic_hp + oc_hp | income + rooms + agehed",
]
mnl = MNLogit(df, utility_formulas, "depvar", covariates=["ic", "oc"])
mnl
<pymc_marketing.customer_choice.mnl_logit.MNLogit at 0x280b78520>
Once we have initialised our model class we can estimate the model with the sample command
mnl.sample()
Sampling: [alphas_, betas, betas_fixed_, likelihood]
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [alphas_, betas, betas_fixed_]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 49 seconds.
Sampling: [likelihood]
<pymc_marketing.customer_choice.mnl_logit.MNLogit at 0x280b78520>
We can then access the fitted inference data object to inspect the posterior estimates for the model parameters of interest.
az.summary(mnl.idata, var_names=["alphas", "betas", "betas_fixed"])
/Users/nathanielforde/mambaforge/envs/pymc-marketing-dev/lib/python3.10/site-packages/arviz/stats/diagnostics.py:596: RuntimeWarning: invalid value encountered in scalar divide
(between_chain_variance / within_chain_variance + num_samples - 1) / (num_samples)
/Users/nathanielforde/mambaforge/envs/pymc-marketing-dev/lib/python3.10/site-packages/arviz/stats/diagnostics.py:991: RuntimeWarning: invalid value encountered in scalar divide
varsd = varvar / evar / 4
/Users/nathanielforde/mambaforge/envs/pymc-marketing-dev/lib/python3.10/site-packages/arviz/stats/diagnostics.py:596: RuntimeWarning: invalid value encountered in scalar divide
(between_chain_variance / within_chain_variance + num_samples - 1) / (num_samples)
/Users/nathanielforde/mambaforge/envs/pymc-marketing-dev/lib/python3.10/site-packages/arviz/stats/diagnostics.py:991: RuntimeWarning: invalid value encountered in scalar divide
varsd = varvar / evar / 4
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| alphas[gc] | 1.379 | 0.755 | 0.072 | 2.912 | 0.021 | 0.012 | 1309.0 | 2162.0 | 1.0 |
| alphas[gr] | 0.358 | 0.837 | -1.213 | 1.958 | 0.023 | 0.014 | 1347.0 | 2084.0 | 1.0 |
| alphas[ec] | 0.803 | 1.016 | -0.987 | 2.876 | 0.024 | 0.015 | 1733.0 | 2379.0 | 1.0 |
| alphas[er] | 2.349 | 0.917 | 0.575 | 4.068 | 0.023 | 0.014 | 1541.0 | 2238.0 | 1.0 |
| alphas[hp] | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | NaN | 4000.0 | 4000.0 | NaN |
| betas[ic] | -0.002 | 0.001 | -0.003 | -0.000 | 0.000 | 0.000 | 3655.0 | 2785.0 | 1.0 |
| betas[oc] | -0.007 | 0.002 | -0.010 | -0.004 | 0.000 | 0.000 | 4317.0 | 3095.0 | 1.0 |
| betas_fixed[gc, income] | -0.061 | 0.086 | -0.212 | 0.112 | 0.002 | 0.001 | 1823.0 | 2203.0 | 1.0 |
| betas_fixed[gc, rooms] | -0.004 | 0.084 | -0.157 | 0.157 | 0.002 | 0.001 | 1583.0 | 2316.0 | 1.0 |
| betas_fixed[gc, agehed] | 0.016 | 0.011 | -0.003 | 0.038 | 0.000 | 0.000 | 1505.0 | 2259.0 | 1.0 |
| betas_fixed[gr, income] | -0.169 | 0.097 | -0.348 | 0.015 | 0.002 | 0.001 | 1992.0 | 2640.0 | 1.0 |
| betas_fixed[gr, rooms] | -0.018 | 0.096 | -0.188 | 0.173 | 0.002 | 0.001 | 1745.0 | 2261.0 | 1.0 |
| betas_fixed[gr, agehed] | 0.020 | 0.012 | -0.004 | 0.042 | 0.000 | 0.000 | 1615.0 | 2343.0 | 1.0 |
| betas_fixed[ec, income] | -0.053 | 0.112 | -0.263 | 0.148 | 0.002 | 0.002 | 2205.0 | 2851.0 | 1.0 |
| betas_fixed[ec, rooms] | 0.049 | 0.108 | -0.148 | 0.256 | 0.003 | 0.001 | 1849.0 | 2686.0 | 1.0 |
| betas_fixed[ec, agehed] | 0.021 | 0.014 | -0.004 | 0.047 | 0.000 | 0.000 | 1850.0 | 2506.0 | 1.0 |
| betas_fixed[er, income] | -0.090 | 0.105 | -0.293 | 0.098 | 0.002 | 0.002 | 2067.0 | 2501.0 | 1.0 |
| betas_fixed[er, rooms] | 0.024 | 0.102 | -0.170 | 0.208 | 0.002 | 0.002 | 1721.0 | 2422.0 | 1.0 |
| betas_fixed[er, agehed] | -0.005 | 0.013 | -0.029 | 0.020 | 0.000 | 0.000 | 1723.0 | 2339.0 | 1.0 |
| betas_fixed[hp, income] | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | NaN | 4000.0 | 4000.0 | NaN |
| betas_fixed[hp, rooms] | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | NaN | 4000.0 | 4000.0 | NaN |
| betas_fixed[hp, agehed] | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | NaN | 4000.0 | 4000.0 | NaN |
Note here how the beta coefficients attaching to the installation and operating costs are negative implying that unit increases in cost drive a decrease in latent subjective utility across the consumer base. It’s this kind of behaviourial insight about the attributes of each product that these models are intended to uncover.
However, some care must be taken in the interpretation of the parameters in these models. Fundamentally discrete choice models are species of causal-inference model where we aim to not merely make inferences about relations in data but make claims about the causal effects of changes in product attributes e.g. how does the market respond to price changes? The criteria of adequacy of a discrete choice model is keyed to how plausible they are as guides to future action and action under counterfactual settings.
New Pricing Intervention#
Consider the following intervention? How might the consumer popoulation respond to a price intervention which targets a particular market segment? We can fit the multinomial logit model as before under a pricing intervention.
new_policy_df = df.copy()
new_policy_df[["ic_ec", "ic_er"]] = new_policy_df[["ic_ec", "ic_er"]] * 1.5
idata_new_policy = mnl.apply_intervention(new_choice_df=new_policy_df)
Sampling: [likelihood]
Then we can inspect how the market share allocated to each of the products is updated after this pricing intervention. On the one hand it makes sense to see a drop in demand for the electrical heating systems which just saw a price increase. However, we can also note a curious fact about the share allocation for the three remaining goods. Each of the goods absorbs an equal 0.08 lift in their market share. This is not a fluke.
The observation stems from IIA property of the multinomial logit model. Under counterfactual interventions market changes lead to somewhat counter intuitive patterns of market substitution. The remaining goods on the market exhibit proportional substitution, where all remaining choices “compete” equally. This is often a quite implausible assumption about market behaviour because it fails to respect properties of market structure or preference. In our case we may wonder if consumers inclined towards electrical heating systems would all equally flock to gas systems of if their is an inherent market bias among that consumer base towards the more eco-friendly heat pump systems?
change_df = mnl.calculate_share_change(mnl.idata, mnl.intervention_idata)
change_df
| policy_share | new_policy_share | relative_change | |
|---|---|---|---|
| product | |||
| gc | 0.636065 | 0.689558 | 0.084101 |
| gr | 0.143567 | 0.155683 | 0.084398 |
| ec | 0.071026 | 0.042900 | -0.396003 |
| er | 0.093405 | 0.050972 | -0.454290 |
| hp | 0.055937 | 0.060887 | 0.088481 |
fig = mnl.plot_change(change_df, figsize=(20, 8))
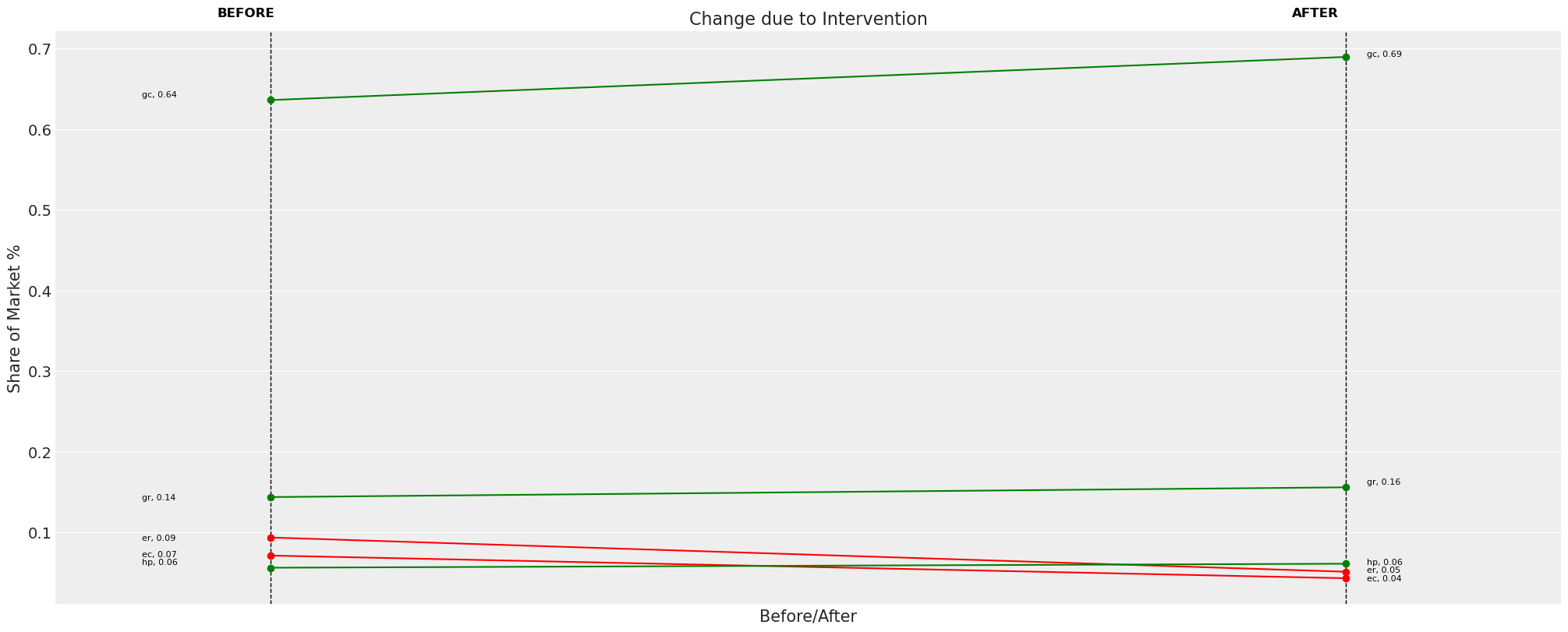
The idea of structural preference or non-proportional substitution patterns simply cannot be accounted for with the multinomial logit model. This is occasionally called the Red-Bus, Blue Bus paradox because the model property implies that even in a transport market with a 50% between a car and bus. If we introduce another bus similar in all respects to the original, then the new market is split equally between the three goods yielding a 33% share for each. This seems wrong because a new bus should only cannibalise market share from the bus consumers.
Let’s see how this pattern plays out in our example. We can remove a product as follows and re-estimate our multinomial logit.
Market Product Intervention#
new_policy_df = df.copy()
new_policy_df = new_policy_df[new_policy_df["depvar"] != "hp"]
new_utility_formulas = [
"gc ~ ic_gc + oc_gc | income + rooms + agehed",
"gr ~ ic_gr + oc_gr | income + rooms + agehed",
"ec ~ ic_ec + oc_ec | income + rooms + agehed",
"er ~ ic_er + oc_er | income + rooms + agehed",
#'hp ~ ic_hp + oc_hp | income + rooms + agehed'
]
idata_new_policy = mnl.apply_intervention(
new_choice_df=new_policy_df, new_utility_equations=new_utility_formulas
)
Sampling: [alphas_, betas, betas_fixed_, likelihood]
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [alphas_, betas, betas_fixed_]
Sampling 4 chains for 2_000 tune and 1_000 draw iterations (8_000 + 4_000 draws total) took 145 seconds.
Sampling: [likelihood]
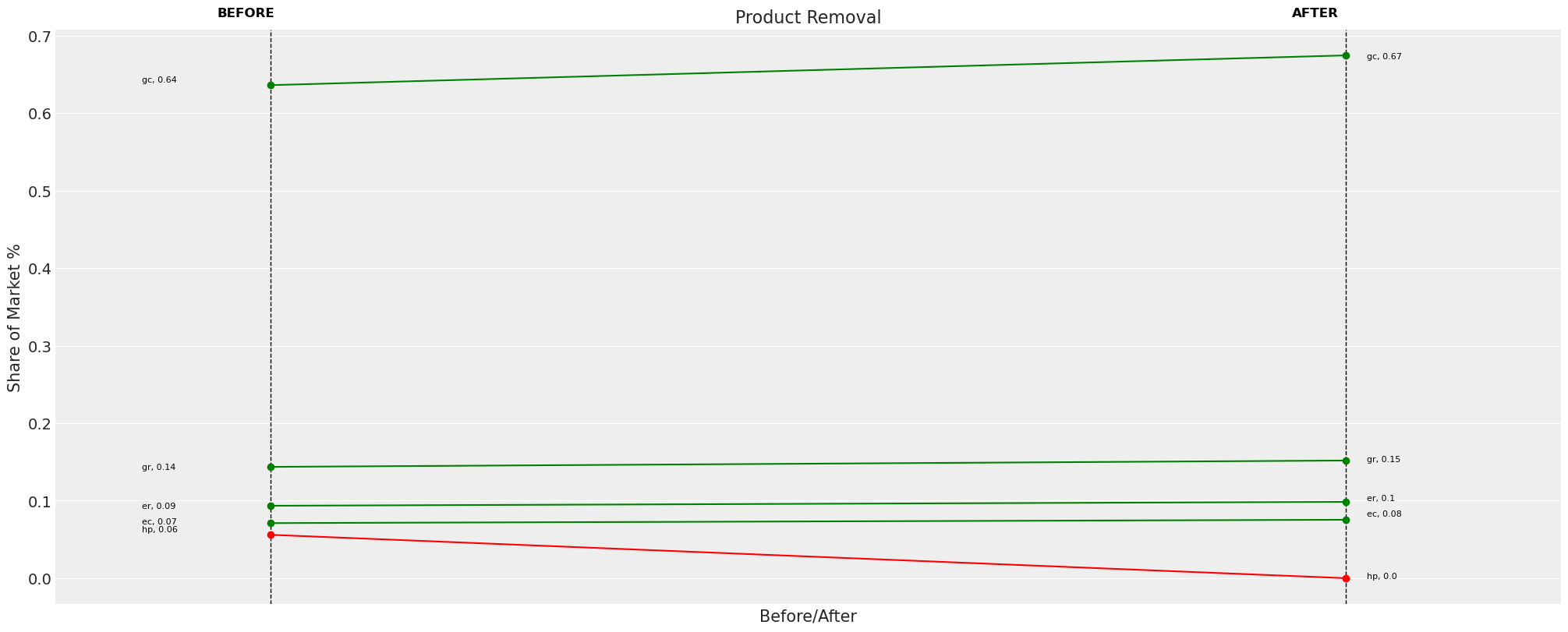
Here agains we see a basically proportional re-allocation where the market demand is re-allocated equally across the remaining goods.
change_df = mnl.calculate_share_change(mnl.idata, mnl.intervention_idata)
change_df
| policy_share | new_policy_share | relative_change | |
|---|---|---|---|
| product | |||
| gc | 0.636065 | 0.674460 | 0.060364 |
| gr | 0.143567 | 0.151770 | 0.057142 |
| ec | 0.071026 | 0.075343 | 0.060773 |
| er | 0.093405 | 0.098427 | 0.053764 |
| hp | 0.055937 | 0.000000 | -1.000000 |
fig = mnl.plot_change(change_df, title="Product Removal", figsize=(20, 8))
Counterfactual Plausibility as a Criteria of Adequacy#
Kenneth Train observes that
“[The IIA] property can be seen either as a restriction imposed by the model or as the natural outcome of a wellspecified model that captures all sources of correlation over alternatives into representative utility, so that only white noise remains. Often the researcher is unable to capture all sources of correlation explicitly, so that the unobserved portions of utility are correlated and IIA does not hold.” - pg 76 in “Discrete Choice Methods with Simulation”
which suggests that the Multinomial Logit model can have a compelling role in markets where the structure of the preferences aren’t governed by anything we haven’t included in the utility equations. But given the difficulty of such a comprehensive model specification we might want to seek alternative model specifications that can support more plausible counterfactual inference about the patterns of market substitution under intervention. One such model specification is the nested logit model.
%load_ext watermark
%watermark -n -u -v -iv -w -p pytensor
Last updated: Wed Jun 18 2025
Python implementation: CPython
Python version : 3.10.17
IPython version : 8.35.0
pytensor: 2.31.3
arviz : 0.21.0
pymc_marketing: 0.14.0
pandas : 2.2.3
matplotlib : 3.10.1
Watermark: 2.5.0